1. The Machine Learning Landscape
TERM
- Training set : The examples that system uses to learn
- Training instance(sample) : EachU training example
- Accuracy : The particular performance measure
- Data Mining : Applying ML techiques to dig into large amounts of data can help discover patterns that were not immediately apparent
- Labels : training data you feed to the algorithm includes the desired solution
(예측하고자 하는 항목 =+= 정답지)
- Learning rate : how fast they should adapt to changing data
CHAPTER 1) The Machine Learning Landscape
: clarifying what ML is & why we may want to use it.
1. What?
2. Why Use?
-
automatically learn → much shorter / easier to maintain / most likely more accurate
-
ML can help humans learn
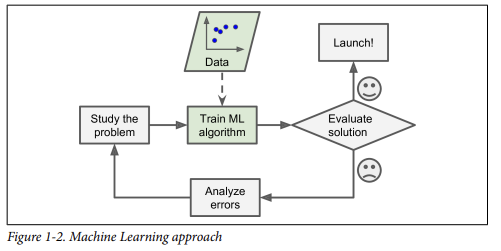
3. Types
- whether or not they are trained with human supervision
: supervised / unsupervised / semisupervised / Reinforcement Learning
- whether or not they can learn incrementally on the fly
: online / batch learning
- simply comparing new data points to known data points
vs detect patterns in the training data and build a predictive model
: instance-based / model-based Learning
A) Supervised / Unsupervised Learning
: classified according to the amount and type of supervision they get during training.
- Supervised Learning(지도 학습)
⇒ classification(분류)
⇒ regression(회귀) : predict a target numeric value given a set of features(=attribute)(predictors)
-Most important SL Algorithm
: k-Nearest Neighbors / Linear Regression / Logistic Regression / Support Vector Machines/Decision Trees and Random Forests / Neural networks
- Unsupervised Learning(비지도 학습)
-Most important SL Algorithm
- Clustering(K-Means/DBSCAN/Hierarchical Cluster Analysis(HCA))
: detect groups of similar features. / find connections without help
-hierarchical clustering Algorithm : subdivide each group into smaller groups
- Anomaly(변칙) detection and novelty detection(One-class SVM/Isolation Forest)
: : detecting unusual transactions to prevent fraud, catching manufactoring defects, automatically removing outliers from db.
+=+Novelty detection : see only normal data
- Visualization and Dimensionality Reduction
(Principal Component Analysis(PCA)/Kernel PCA/Locally-Linear Embedding(LLE),t-distributed Stochastic Neighbor Embedding(t-SNE))
: -Visualization Algorithm : output a 2D or 3D representation of data that can easily be plotted.
+=+Dimensionality reduction : simplify the data without losing too much information.
⇒ run much faster, less disk&memory space, perfom better
+=+Feature extraction : merge several correlated features into one.
- Asscoiation rule learning(Apriori/Eclat)
: dig into large amounts of data and discover interesting relations between attributes.
- Semisupervised Learning(반지도 학습)
- Reinforcement Learning(강화 학습)
: must learn by itself what is the best strategy = policy
cf) Alphago
B) Batch / Online Learning
: whether or not the system can learn incrementally(점진적으로) from a stream of incoming data
- Batch Learning
Offline Learning : First the system is trained, and hen it is launched into production and runs without learning anymore
⇒ if, ++ new data ⇒ train a new version of the system from scratch on the full dataset, then stop the old system and replace it with the new one
😓DIsadvantages😓
⇒ take a lot of time/computing resources/money ⇒ done offline
⇒ if amount of data is huge, may be IMPOSSIBLE
😀Advantages😀
⇒ simple and often works fine
- Online Learning
: mini-batches (mini batches 뭉탱이 sequentially)
-out-of-learning
😀Advantages😀
⇒ fast and cheap
⇒ change rapidly & autonomously
⇒ save a huge amount of space.
😓DIsadvantages😓
⇒ High Learning rate → rapidly adapt to new data, BUT quickly forget the old data
⇒ Low Learning rate → learn more slowly, BUT less sensitive to noise
⇒ if bad data is fed → clients will notice that performance will gradually decline.
C) Instance-Based / Model-Based Learning
: How they generalize
- Instance-based Learning
: certainly not the best.
KNN
- Model-based Learning
model selection → utility function=fitness function(measure how good my model is) / define cost function
→ study the data
→ select a model
→ trained it (the learning algorithm searched for the model parameter values that minimize a cost function)
→apply the model to make predictions on new cases(=inference), hoping that this model will generalize well.
4. Main Challenges of Machine Learning
: Bad Algorithm / Bad data
1) Insufficient Quantity(양) of Training Data
: Even for very simple problems, typically need thousands of examples.
2) Nonrepresentative Training Data
: training data be representative of the new cases you want to generalize to
⇒ if not , unlikey to make accurate predictions
sample is small → sampling noise
sample is large → sampling bias /ex) Roosvelt_Literary Digest
3) Poor-Quality Data
: will make it harder for the system to detect the underlying patterns → less likely to perform well.
→ 多 spend time cleaning up your training data.
4) Irrelevant Features
: “Garbage in, Garbage out”
-feature engineering : coming up with a good set of features to train on(enough relevant features & not too many irrelevant)
-feature selection : selection the most useful features to train on among existing features.
-Feature extraction : combing existing features to produce a more useful one
-creating new features by gathering new data
5) Overfitting the Training Data
: the model performs well on the training data, but it does not generalize well.
: it happens when the model is too complex relative to the amount and noises of the training data.
: find the right balance : fitting the training data perfectly & keeping the model simple enough to ensure that it will generalize well.
-To simplify the model by selecting one with fewer parameters
-To gather more training data
-To reduce the noise
- Regularization : Constraining a model to make it simpler and reduce the risk of overfitting.
cf) Training error(LOW) & Generalization error(HIGH) ⇒ OVERFITTING
6) Underfitting the Training Data
: occurs when the model is too simple to learn the underlying structure of the data.
-Selecting a more powerful model, with more parameters
-Feeding better features to the learning algorithm( feature engineering)
-Reducing the constraints on the model.
